Building a Smart, Private Chatbot with Local Content Search and Function Calling with APIs using Semantic Kernel and Ollama
1. Introduction
This article integrates Semantic Kernel (SK), Ollama, and Qdrant to build a local retrieval-augmented generation (RAG) system with function-calling capabilities. This chatbot is developed with custom plugins, including a RAG based plugin with PDF Search, LocalDateTime Plugin and a Weather Plugin, allowing it to answer queries beyond basic conversation, such as providing relevant answer from embedded content, getting the current local time and weather information. This article explains the architecture, tech stack, setup instructions, and a detailed code walkthrough.
Architecture Diagram
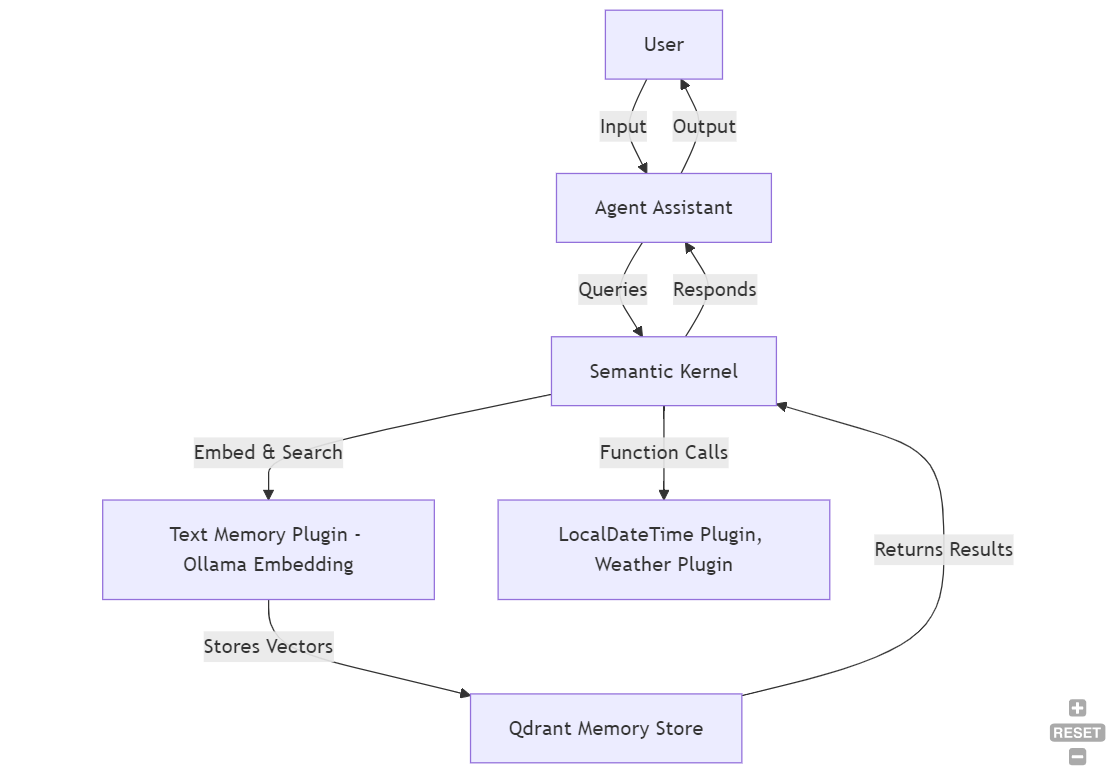
2. Tech Stack Summary
Semantic Kernel
Microsoft Semantic Kernel enables the integration of language models with external tools and plugins, allowing advanced interactions like embeddings, memory search, and plugin-based function calling.
Ollama
Ollama is used for generating text embeddings that are vector representations of text. These embeddings are critical for tasks like semantic search and information retrieval.
Qdrant
Qdrant is a vector database that stores embeddings generated by Ollama. It enables fast similarity search, which is essential for retrieving contextually relevant information based on user input.
3. Setup Instructions
Setting up Ollama
Download the Ollama software from the following URL https://ollama.com/download and follow the instructions to download and run the model locally.
ollama pull llama3.1 |
Setting up Qdrant Using Docker
Download and Install the Docker Desktop from the official website.
Pull the Qdrant Docker image:
docker pull qdrant/qdrantRun Qdrant with Docker:
docker run -p 6333:6333 qdrant/qdrantVerify if Qdrant is running:
http://localhost:6333/dashboard
4. Code Walkthrough
Configuration Setup
var config = new ConfigurationBuilder() |
This section loads secret keys and model configurations required to run the assistant.
{ |
Replace "baseUrl" and "baseEmbeddingUrl" with ollama base url , "qdrantMemoryStoreUrl" with your qdrant server url, and "weatherApiKey" with your api keys from weatherapi.com
Memory Setup
var memory = new MemoryBuilder() |
This creates a memory builder using Ollama for text embeddings and Qdrant to store them.
Kernel Initialization
var builder = Kernel.CreateBuilder() |
The kernel integrates the OpenAI chat completion interface for generating chat responses and manages plugin execution for custom functionalities.
Prompt Instructions
In the context of the Semantic Kernel, prompt instructions serve as a guiding light for the LLM, influencing its decision-making process when choosing the appropriate plugin to execute. Well-crafted prompt instructions have a profound impact on the LLM’s ability to choose the correct plugin and deliver accurate results. They bridge the gap between human intent and machine understanding, enabling seamless function calling and a more natural user experience. So, always ensure clear, specific, and comprehensive prompt instructions to unlock the full potential of your LLM.
string HostInstructions = $@"You are an Assistant to search content from the {domainName} guide to help users to answer the question. |
Agent and Plugins Setup
ChatCompletionAgent agent = new() |
Here, the ChatCompletionAgent is initialized with specific instructions. Plugins such as TextMemoryPlugin, LocalDateTimePlugin, and WeatherPlugin are registered to extend the assistant’s functionality.
Initialize Chat Loop
while (true) |
This loop continuously prompts the user for input and invokes the agent to process the queries using memory and plugins.
Embedding Data
async Task EmbedData() |
The function uses the PDF Loader from Kernel Memory Library and pass every page content to ollama embedding API to embed the data and store it into Qdrant vector database for later retrieval.
LocalDateTimePlugin
public sealed class LocalDateTimePlugin |
This plugin retrieves the current local time and can be invoked by the assistant to answer time-related queries.
WeatherPlugin
public sealed class WeatherPlugin(string apiKey) |
The WeatherPlugin interacts with an external API to fetch weather details for a given location. The user can ask the assistant about the weather, and it will utilize this plugin.
Ollama TextEmbedding Generation
public class OllamaTextEmbeddingGeneration : ITextEmbeddingGenerationService |
This service generates embeddings for input text using Ollama and stores the embeddings in Qdrant for efficient search and retrieval.
Memory Builder Extensions
public static class OllamaMemoryBuilderExtensions |
This extension method simplifies the integration of Ollama into the memory building process.
5. Final Output
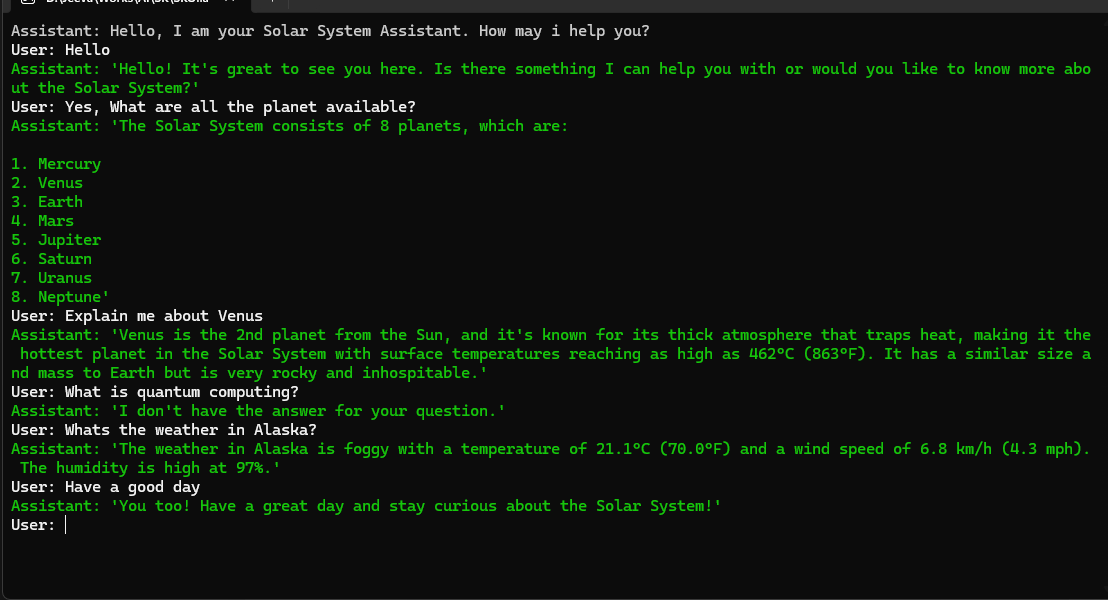
This article demonstrates the power of combining local LLMs function calling and RAG with the Semantic Kernel framework. By leveraging Ollama for embeddings and Qdrant for efficient vector storage, you can create a chatbot that understands your domain-specific knowledge and interacts with external services. The ability to run LLMs locally enhances data privacy and control, making it a compelling solution for various enterprise applications. The entire source code is available here in the following github url.
https://github.com/vavjeeva/SKOllamaLocalRAGSearchWithFunctionCalling
Disclaimer: Please note that the code is based on the current version of the Semantic Kernel. Future updates to the framework may introduce changes that could impact the compatibility or functionality of this code. It’s always recommended to refer to the official Semantic Kernel documentation and stay updated with the latest releases.