Harnessing the Power of Function Calling with Local LLMs using Ollama - A Dive into Llama 3.1 and Semantic Kernel
Introduction
The usage of large language models (LLMs) has revolutionized the way we approach complex tasks in AI, providing powerful tools for natural language understanding, generation, and more. Among the collection of LLMs available, Meta's Latest Llama 3.1 stands out as a robust model for various natural language processing (NLP) applications. Coupled with Microsoft's Semantic Kernel, developers now have a flexible framework to integrate these models into a wide range of applications, from chatbots to data analysis tools etc..
In this article, we'll explore the exciting capabilities of function calling using a local instance of Llama 3.1 hosted in ollama with Semantic Kernel. By leveraging this combination, developers can harness the full potential of Llama 3.1 while maintaining control over their data and computational resources with out using any cloud services. We’ll walk through the process of setting up a local LLM environment, integrating it with Semantic Kernel, and implementing function calling to perform specific tasks.
Why Use a Local LLM with C# Semantic Kernel?
Running LLMs locally brings several key advantages:
- Data Security: Your data remains within your local environment, ensuring privacy and compliance with data protection regulations.
- Customization: You can select various open source models that better suit specific use cases. SLM model like PHI3 for simple use case like summarization.
- Cost Savings: Avoiding the need for external APIs reduces ongoing costs.
- Low Latency: Local execution minimizes response times, improving performance for real-time applications.
The C# Semantic Kernel library provides a structured framework for integrating LLMs into your applications. It simplifies the process of calling functions, managing context, and orchestrating complex workflows, making it easier to deploy Llama 3.1 in real-world scenarios.
Setting Up Llama 3.1 Locally with Ollama
To begin function calling with a local instance of Llama 3.1 using C# Semantic Kernel, you'll need to follow a few setup steps.
First, you’ll need to set up the Llama 3.1 model from Ollama on your local machine. This involves:
- Hardware Preparation: Ensure your machine has the necessary computational power, preferably a GPU.
- Environment Configuration: Install the required software and dependencies. Follow the instructions provided by Ollama to download and run Llama 3.1 locally.
Step-by-Step Guide: Implementing Function Calling with Llama 3.1 Using C# Semantic Kernel
Step 1: Setup Your Project
Create a New C# Console Application:
- Open your preferred IDE (like Visual Studio or Visual Studio Code).
- Create a new Console Application project.
Install Required NuGet Packages:
- Install the following NuGet packages via the NuGet Package Manager or using the .NET CLI:
dotnet add package Microsoft.Extensions.Configuration
dotnet add package Microsoft.SemanticKernel
dotnet add package Microsoft.SemanticKernel.Connectors.OpenAI
- Install the following NuGet packages via the NuGet Package Manager or using the .NET CLI:
Configure User Secrets:
- Set up user secrets to securely store your model ID, base URL, and weather API key. This can be done via the .NET CLI:
dotnet user-secrets init |
- Replace
"your-model-id","your-base-url", and"your-weather-api-key"with your actual values. you can download free weather api key from weatherapi.com
Step 2: Configure the Application
- Load Configuration:
- Start by loading the configuration values from user secrets:
var config = new ConfigurationBuilder() .AddUserSecrets(Assembly.GetExecutingAssembly(), true) .Build();
var modelId = config["modelId"];
var baseUrl = config["baseUrl"];
var weatherApiKey = config["weatherApiKey"];
- Start by loading the configuration values from user secrets:
- Set Up the HTTP Client:
- Initialize an
HttpClientwith a timeout setting to manage the requests to your local Llama 3.1 model:var httpClient = new HttpClient { Timeout = TimeSpan.FromMinutes(2) };
- Initialize an
- Build the Semantic Kernel:
Create and configure the Semantic Kernel using the
KernelBuilder:var builder = Kernel.CreateBuilder()
.AddOpenAIChatCompletion(modelId: modelId!, apiKey: null, endpoint: new Uri(baseUrl!), httpClient: httpClient);
var kernel = builder.Build();
Step 3: Set Up the Chat Agent and Add Plugins
Define Agent Instructions (Prompt) and Settings:
var HostName = "AI Assistant";
var HostInstructions = @"You are a helpful Assistant to answer their queries. Be respectful and precise in answering the queries.
If the queries are related to getting the time or weather, Use the available plugin functions to get the answer.";
var settings = new OpenAIPromptExecutionSettings() { Temperature = 0.0,
ToolCallBehavior = ToolCallBehavior.AutoInvokeKernelFunctions };
ChatCompletionAgent agent = new()
{ Instructions = HostInstructions, Name = HostName, Kernel = kernel, Arguments = new(settings), };Add Plugins to the Agent:
In this section, we will dive into the functionality of two key plugins used in our application: the WeatherPlugin and the LocalTimePlugin. These plugins are designed to handle specific tasks—retrieving weather details and getting the current local time—and they are integrated into the Semantic Kernel to be invoked when needed by the AI Assistant.
- WeatherPlugin
The WeatherPlugin is a class that interfaces with a weather API to fetch and return weather details for a specified location. Here’s a breakdown of how it works:
Functionality:
- The plugin takes in a location name as input from the prompt and queries a weather API to retrieve the current weather conditions for that location.
- It uses an HTTP client to send a GET request to the API, incorporating the provided location and the API key (which is securely stored using user secrets).
Code Explanation:
public sealed class WeatherPlugin(string apiKey) |
Constructor (
WeatherPlugin): Takes an API key as a parameter, which is used to authenticate requests to the weather API.HttpClient: An instance of
HttpClientis created to manage HTTP requests and responses.GetWeatherAsyncMethod: This is the core method of the plugin, decorated with[KernelFunction], indicating that it can be called by the Semantic Kernel:- It constructs the API request URL using the provided location name and API key.
- The method then sends an asynchronous GET request to the weather API.
- Upon receiving a successful response, it reads the content (which contains the weather details) and returns it as a string.
- This plugin is designed to be easily invoked by the Semantic Kernel whenever a user query involves weather information, making it a valuable tool for real-time weather data retrieval.
- LocalTimePlugin
The LocalTimePlugin is a simpler plugin compared to the WeatherPlugin. Its sole purpose is to retrieve and return the current local time on the machine where the application is running.
Functionality:
- The plugin provides the current local time in the format "HH:mm:ss".
- It does not require any external API calls, making it fast and lightweight.
Code Explanation:
public sealed class LocalTimePlugin |
GetCurrentLocalTimeMethod: This static method is also decorated with[KernelFunction]:- It simply fetches the current local time using
DateTime.Nowand formats it as a string in "HH:mm:ss" format. - The method then returns this formatted string, which the AI Assistant can use to respond to user queries about the time.
- This plugin is straightforward for any queries related to getting the current local time.
- It simply fetches the current local time using
Integrating Plugins into Semantic Kernel
Both plugins are integrated into the Semantic Kernel by being registered as KernelPlugin instances. This allows the AI Assistant to automatically invoke these functions when responding to user queries related to weather or local time.
KernelPlugin localTimePlugin = KernelPluginFactory.CreateFromType<LocalTimePlugin>();
agent.Kernel.Plugins.Add(localTimePlugin);
KernelPlugin weatherPlugin = KernelPluginFactory.CreateFromObject(new WeatherPlugin(weatherApiKey!));
agent.Kernel.Plugins.Add(weatherPlugin);
* **`localTimePlugin`**: This plugin is created using `KernelPluginFactory.CreateFromType<LocalTimePlugin>()`, which registers the `LocalTimePlugin` with the Semantic Kernel.
* **`weatherPlugin`**: This plugin is created by passing a new instance of `WeatherPlugin` (with the API key) to the factory, enabling it to fetch weather data dynamically.
Step 4: Implement the Chat Loop
Initialize the Chat Interface:
- Create an instance of
AgentGroupChatto manage the conversation between the user and the agent:
- Create an instance of
AgentGroupChat chat = new(); |
Create a Function to Handle User Input:
Implement a local function that invokes the agent and handles the conversation flow:
async Task InvokeAgentAsync(string question)
{
chat.AddChatMessage(new ChatMessageContent(AuthorRole.User, question));
Console.ForegroundColor = ConsoleColor.Green;
await foreach (ChatMessageContent content in chat.InvokeAsync(agent))
{
Console.WriteLine(content.Content);
}
}
Run the Chat Loop:
- In the main loop, continuously read user input and process it using the
InvokeAgentAsyncfunction:Console.WriteLine("Assistant: Hello, I am your Assistant. How may I help you?");
while (true)
{
Console.ForegroundColor = ConsoleColor.White;
Console.Write("User: ");
await InvokeAgentAsync(Console.ReadLine()!);
}
- In the main loop, continuously read user input and process it using the
Step 5: Run Your Application
- Build and Run the Application:
- Compile the application and run it. You should see the AI Assistant prompt, and you can interact with it by asking questions related to time or weather. *
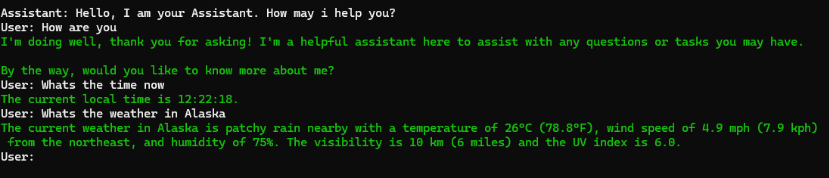
- Compile the application and run it. You should see the AI Assistant prompt, and you can interact with it by asking questions related to time or weather. *
Conclusion
With the steps above, we have successfully implemented a C# Application that uses the Semantic Kernel library with a local instance of the Llama 3.1 model using Ollama that leverages function calling to handle specific tasks like retrieving the local time or weather information, showcasing the flexibility and power of combining local LLMs with function calling using C# Semantic Kernel. The entire source code is available here in the following github url.
https://github.com/vavjeeva/SKAgentLocalFunctionCalling?tab=readme-ov-file